CS:APP 第九章 “Virtual Memory” 的学习笔记。
本章的主要内容为 page table、address translation、memory mapping、dynamic allocation。
虚存是对 main memory 的抽象,它的主要作用有:
- 将 main memory 用作 disk 的 cache,只将 active 的部分放在 main memory,在需要时在 disk 和 memory 之间传递数据
- 通过给应用程序提供统一的地址空间,简化内存管理
- 通过给不同进程提供独立的地址空间,防止一个进程的数据被其他进程破坏
虚存在系统中起着非常重要的作用,学习虚存一方面可以学会使用它的一些强大功能(例如将文件映射到内存中),另一方面可以避免一些内存管理相关的错误。
Physical and Virtual Addressing
内存有两种寻址方式:物理寻址和虚拟寻址。
main memory 可以看作 个 byte 排列在一起,地址分别为 ,物理寻址就是 CPU 直接将需要的地址传给 main memory,获取到数据后传回 CPU。
虚拟寻址需要硬件和操作系统配合,CPU 将虚拟地址传给 memory management unit (MMU),MMU 将虚拟地址翻译成物理地址传给 main memory,而这个过程又和操作系统相关。
Address Spaces
(线性)地址空间是连续的非负整数构成的集合,一个系统有一个物理地址空间 ,还有若干个虚拟地址空间 ,其中 ,称作 -bit 地址空间,一般是 32-bit 或者 64-bit。
同一份数据可以在不同的地址空间有不同的地址,是虚存的一个基本思想。
VM as a Tool for Caching
可以说,虚存是存储在磁盘上的,而物理内存是虚存的 cache。
page
虚存被分成了很多固定大小的块,每一块称作一个 virtual page,而物理内存被分为同样大小的块,每一块被称作一个 physical page。在 cache 中,这样的一块一般被称作一个 block,但在虚存中被称作一个 page。
因为 DRAM 比磁盘快很多,并且磁盘的连续访问比随机访问快很多:
- 虚存的一个 page 会比较大,一般有 4KB ~ 2MB
- 虚存是 fully associative cache
- 操作系统会使用一些比 SRAM cache 更加复杂的算法作为 replacement policy 来管理虚存
一个 virtual page 可能处于三种状态之一: unallocated、cached、uncached。
page table
在物理内存中存放着一张 page table,虚拟地址空间中的每个 page 都对应 page table 中的一项 (page table entry, PTE)。每一项包含一个 valid bit 和一个地址:
- cached: valid bit set,地址为该 page 的缓存的物理地址
- uncached: valid bit not set,地址指向磁盘上的 virtual page
- unallocated: valid bit not set,地址为 null
page fault
在地址翻译时,MMU 会查看传入的虚拟地址对应的 PTE,若 cached,则称作 page hit,就会将 PTE 存储的物理地址传给 main memory;否则,就是 cache miss,在虚存中被称作 page fault。
page fault 是一个 exception,会触发 kernel 中的 page fault handler。page fault handler 会在 physical memory 中选择一个 physical page(victim page)用来存这个触发 page fault 的 page,先将 victim page 原有的数据在必要时放回磁盘,然后将新的数据存入 victim page,再相应地修改 page table 中的这两个 PTE,使得 victim page 原来存的那个 virtual page 变为 uncached,而新存入的 virtual page 变为 cached 并且地址指向 victim page。page fault handler 的最终效果就是,一开始想要的 virtual page 已经 cached,于是在返回到 exception 触发的位置时就可以 page hit 而正常读取数据了。
在磁盘和内存间传递数据在虚存中被称作 swapping 或 paging:
Pages are swapped in (paged in) from disk to DRAM, and swapped out (paged out) from DRAM to disk.
虚存的 cache miss 是非常昂贵的,但由于程序访问内存的 locality,一般来说 page fault 很少触发,效率就不会太差。不断触发 page fault 的情况称作 thrashing,会大大影响程序的效率。
VM as a Tool for Memory Management
实际上,page table 在一个系统中并非只有一份,而是每个进程都有一份,并且可以把同一个 physical page 映射到不同进程中的多个 virtual page。
虚存为内存管理提供了如下的便利:
- 简化了 linking,使得链接时无需考虑具体的物理地址,不同程序可以使用同样的虚拟地址分配方案。
- 简化了 loading,使得加载程序时只需将可执行文件的段落映射到虚存中,不用拷贝数据,等访问到某个 page 时才会 page in。这样的将文件内容映射到虚存中的操作称作 memory mapping,Linux 提供了
mmapsystem call 来进行 memory mapping。 - 简化了内存共享,操作系统可以将进程私有的数据映射到不同的 physical page,而将共享的数据映射到相同的 physical page。
- 简化了内存分配,因为应用请求一段连续的 virtual pages 时,操作系统可以将其映射到不连续的 physical pages。
VM as a Tool for Memory Protection
- 虚存可以轻松地给不同的进程提供不同的私有内存空间。
- 通过给 PTE 添加 permission bit
SUP、READ、WRITE,就可以使某个 page 只读或者只能在 kernel mode 下被访问。如果试图访问一个 page 时权限出错,则会触发 CPU 的 general protection exception,进而由 exception handler 向进程发送 SIGSEGV。
Address Translation
一个内存地址可以被分为两部分,虚拟地址被分为高位的 virtual page number (VPN) 和低位的 virtual page offset (VPO),物理地址被分为 PPN 和 PPO。
CPU 中有一个 page table base register (PTBR),指向 page table 的起始地址。地址翻译时,MMU 通过 PTBR 和 VPN 得到 PTE 的地址,从 main memory 获取 PTE,根据 valid bit,要么触发 page fault,要么获取到 PPN,而 PPO = VPO,就得到了物理地址。
SRAM cache 一般会以物理地址来 cache main memory,也就是说,通过 PTE 的地址访问 PTE、通过物理地址访问 main memory 时会首先尝试通过 SRAM cache 来访问。
如果每次都从 main memory 获取 PTE,即使在 L1 cache hit 了效率也不够高,所以 MMU 中还有一个小的 page table cache,叫做 translation lookaside buffer (TLB)。VPN 被分为两部分:低位的 TLBI (index) 和高位的 TLBT (tag),其中 TLBI 用来选择 cache set,TLBT 用来进行 cache line matching。在地址翻译时,会优先查询 TLB,若 miss 再查询 page table。
地址空间往往很大,如果只用一张 page table,那么 page table 本身就会占用大量的空间,所以可以将 page table 分层,每层 page table 指向下一层 page table,直到最后一层指向 VP / PP。
Case Study: Core i7 Address Translation
Core i7 memory system 如 CS:APP Figure 9.21 所示:
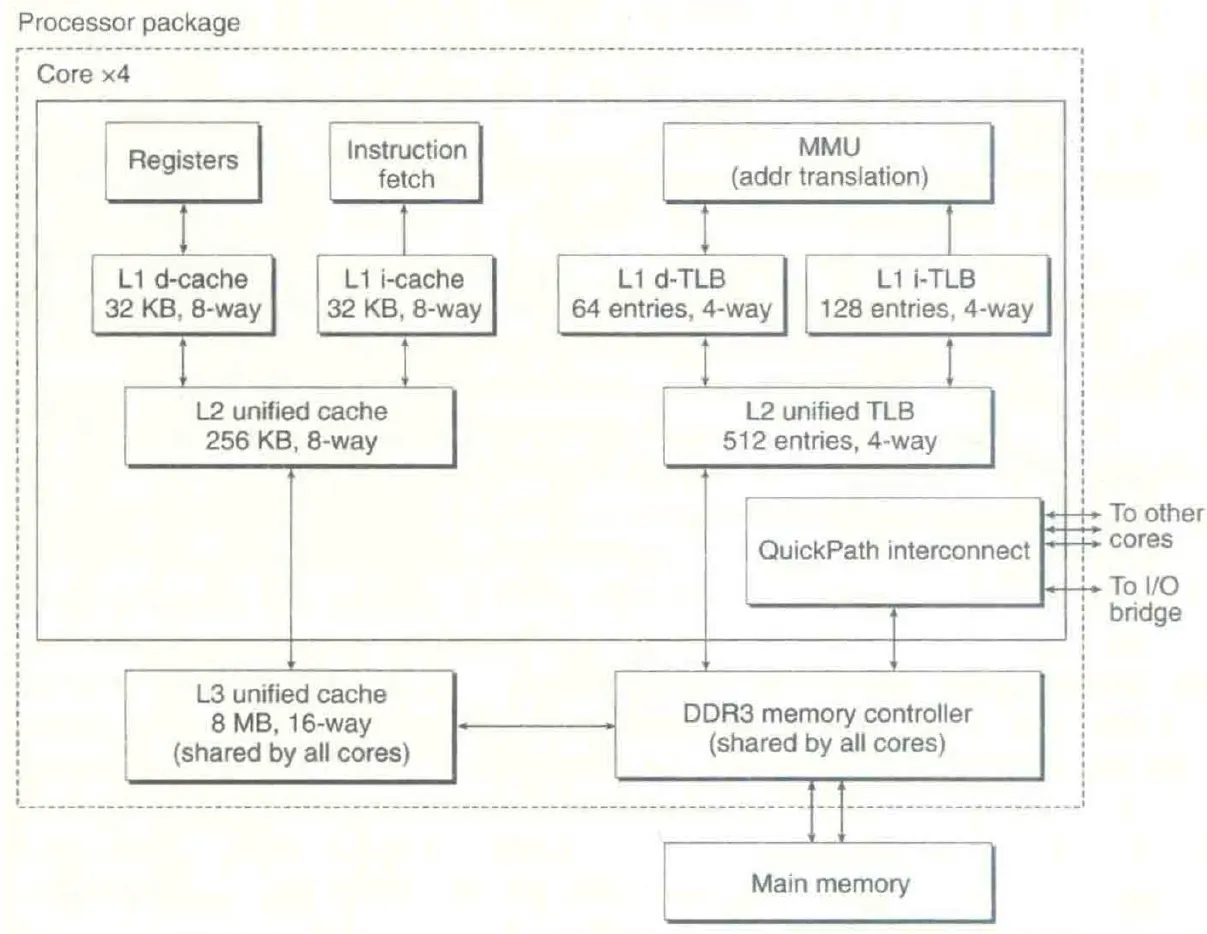
Core i7 使用 48-bit 的虚拟地址空间和 52-bit 的物理地址空间,page size 可以设置为 4KB 或 4MB,有四级 page table。
每个 PTE 有以下内容:
- P: valid bit
- R/W: 是否只读
- U/S: 是否需要在 kernel mode 下访问
- XD: 是否可以被读取指令(是否可执行)
- A: reference bit,访问到时由 MMU 设置,而由软件清除(可以用于 replacement algorithm)
- Base addr: child page table / physical page 的地址的高位 40 bits(剩下 12 bits 即 4KB,这要求地址以 4KB 对齐,而 page size 一般就是 4KB)
L1 page table 还有一项 PS 用来指定 page size。
L4 page table 还有 dirty bit D 用来表示 page 被写入过需要被 swap out (write back),以及 G 表示 global page 即切换进程时不从 TLB 中 evict 掉。
VPN 有 36 bits,每 9 bits 用来访问一级 page table。
因为 L1 cache 是 8-way 32KB 的,正好有 12 bits 用来选择 cache set,所以在获取 PPN 的同时就可以把 VPO 发送给 L1 cache 来提前选择好 cache set。
Linux Virtual Memory System
kernel 的虚存中包含:
-
kernel 的代码以及全局的数据结构
-
将整个物理内存连续地映射到虚存中,这样就可以方便地访问特定的物理地址
-
和每个进程相关的数据结构,例如 page table、kernel stack、
task_struct等(P.S. 这部分虽然是和每个进程相关,但并不会在每个进程中有所不同,CS:APP 中这里写错了,在 errata 中指出了)
Linux 将虚存划分为若干 area(也称 segment)来管理,例如 code segment、data segment、heap、shared library segment,每个 area 是虚存中连续的一段。
kernel 为每个进程维护了一个 task_struct,其中的 mm 一项是一个 mm_struct。mm_struct 的 pgd 一项是 L1 page table 的地址,而 mmap 指向一个 vm_。每个 vm_ 表示一个 area,有以下几项(还有一些其他项):
vm_start/vm_end: 指向 area 的开头 / 结尾vm_page_prot: area 中所有 page 的 access permissionvm_flags: 一些 flag,例如这个 area 中的 page 是否被所有进程共享vm_prev/vm_next: 指向相邻的vm_,构成一个链表area_ struct
在处理 page fault 时,page fault handler 首先会检查地址是否在某个 area 内(不在则触发 segmentation fault),然后会检查是否有访问权限(没有则触发 protection exception),如果一切 ok 就会根据 replacement algorithm 选择 victim page,若其 dirty 则将其 swap out,然后将新的 page swap in,最后更新 page table 并返回。
Memory Mapping
将一个 object 的内容设为一段虚存的初始值称作 memory mapping。这个 object 可以是文件系统中一个文件的一段 (file-backed),也可以是一个初始为空的 anonymous file (demand-zero)。
在 map 时并不会立即将数据放到物理内存中,而是等到访问到某个 page 时再 swap in,这称作 demand paging。操作系统会使用 swap file 来进行 swapping,但只有进行了修改才会需要 swap out,否则可以直接从 map 到的文件 swap in。
如果不同的进程映射到了同一个文件的同一段,在物理内存中会只有一份数据。
memory mapping 有 shared 和 private 两种:
- map as shared objects: 修改对其他进程可见,如果是 file-backed 还会将内存修改同步到磁盘上的文件。
- map as private objects: 修改对其他进程不可见,也不会同步到磁盘上,并且是 copy-on-write 的:一开始将 PTE 设为只读,在触发 protection exception 后,exception handler 发现这个 area 是可以写入但 private 的,就创建一个新的 page,将原来的 page 复制过去,将 PTE 设为可以写入。
fork 的原理
fork 时会将原来的 mm_struct 以及 page table 复制一份,但是将原来的 private area 中的 PTE 可以写入的重新变为只读,从而在之后再写入时重新触发 copy-on-write,就做到了 parent 和 child 一开始有一样的数据但后续写入独立。在 fork 前就创建了的 shared area 会由两个进程共享,可以利用这一点在 parent 和 child 之间通信。
execve 的原理
- 删除当前进程的所有 area (
vm_)area_ struct - 根据 program header table 进行 memory mapping:
.init、.text、.rodata: private, file-backed, read-only.data: private, file-backed, read/write.bss、heap、stack: private, demand-zero, read/write
- 如果有 link 到共享库,会进行动态链接,将共享库 private, file-backed map
- 修改 program counter
mmap
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)
addr: area 的起始地址,仅作提示作用,一般NULL就行length: area 的长度prot:PROT_EXEC、PROT_READ、PROT_WRITE、PROT_NONEflags: 有很多,常用的有MAP_SHARED、MAP_PRIVATE、MAP_ANONYMOUS fd: map 到的 file descriptoroffset: map 到的文件内容的 offset,必须是 page size 的倍数
在 MAP_ 时,最好将 fd 设为 -1、offset 设为 0(在有的实现中这是必须的)。
失败时 mmap 会返回 MAP_FAILED。
int: 将自 addr 起 length 长的范围内的 mapping 删除,以后再访问就会 segmentation fault。addr 必须是 page size 的倍数。
Dynamic Memory Allocation
动态分配的相关函数
在 C 语言中,可以用 malloc 和 free 来获取 / 释放动态分配的内存。可以使用 calloc 来初始化分配到的内存并在使用乘法计算内存大小时检测是否发生溢出。可以使用 realloc 来给一块动态分配的内存调整大小。详见 man malloc。
为了让动态分配得到的内存可以用于任何数据类型,地址会以 double word 对齐,即 32 位系统对齐到 8 的倍数,64 位系统对齐到 16 的倍数。
操作系统使用 brk 指针来指向 heap 的结尾,可以通过 sbrk 函数来增大 heap。
allocator 的要求和目标
Dynamic memory allocator 会将 heap 划分为若干大小不等的 block,每个 block 要么 allocated 要么 free。
allocator 需要做到:
- 能够处理以任意顺序发送的 allocate 和 free 请求(不能对顺序做任何假定)
- 立即对请求做出响应(不能离线)
- 只使用 heap 存储数据(不能将数据存储在虚存的其他位置)
- 满足对齐要求(能够存储任何类型的数据)
- 不能修改或移动 allocated block(可以修改 free block 或者 heap 中不是 block 的区域)
而 allocator 有两个性能方面的目标:
- 更快地响应请求(更大的吞吐量)
- 更高效地利用内存
其中,导致内存利用率低的主要原因是 fragmentation:
- internal fragmentation: 实际分配的 allocated block 比 alloc 请求中申请的大
- external fragmentation: 所有 free block 加起来大小足够,但每单个 free block 都不够大,导致需要使用更多 heap 空间
一种简单的 allocator 实现方式
block header
allocator 需要记录 block 的信息,而只能使用 heap 空间,所以直接在 block 的开头记录 block header,即 block size 以及是否 allocated。
因为地址有对齐要求,block size 的最低几位一定是 0,就可以用最低位来存 allocated bit。
block size 充当了单向链表的作用。如果想访问 free block,就得访问每个 block 再看是否 free,所以这样的结构被称作 implicit free list。
placement policy
allocate 时需要找到一个足够大的 free block,allocator 进行这样的搜索的方式称作 placement policy:
- first fit:从头开始找,直到找到足够大的 free block
- next fit:从上次搜索结束的地方开始找,直到找到足够大的 free block
- best fit:遍历所有 free block,使用足够大的 free block 中最小的
使用 implicit free list 时,next fit 比 first fit 吞吐量更大但内存利用率更低,best fit 内存利用率最好但吞吐量最差。
分割 free block
如果 allocate 时 free block 的剩余空间比需要的空间大,且大的超过一个 block 的 minimum size (double word),就可以将这个 block 分为两半,一半用作 allocated block,另一半为 free block。
获取更多的 heap 空间
如果已有的 heap 空间无法满足 allocate 请求,可以使用 sbrk 来获取更多的 heap 空间,并将新得到的空间设为 free block。
合并 free block
如果很多 free block 相邻地放在一起,可能会造成 false fragmentation,即合并后能放下但每个单独无法放下,所以需要对相邻的 free block 进行合并 (coalesce)。
合并有两种策略:
- immediate coalescing:每次 free 时都将新得到的 free block 与相邻的 free block 合并,这样的话每时每刻都不会有相邻的 free block
- deferred coalescing:等到某个时候再合并,例如在未能找到足够大的 free block 时
immediate coalescing 的实现较为简单,可以在常数时间内完成,但可能会导致反复的合并和分割,带来不必要的性能损失。
合并时需要知道上一个 block 的信息,这可以通过在 block 尾部添加一个与 header 内容相同的 footer 来实现,这被称作使用 boundary tags。由于只有 free block 需要 footer,可以省去 allocated block 的 footer,而在 header 中存储上一块的 allocated bit,来节省空间。
explicit free list
可以在 free block 中存储指向前驱后继的指针来维护一个 free block 的链表,称作 explicit free list。
这个 list 可以是 LIFO 的或者按地址顺序的。LIFO 的 list 可以在常数时间内完成 free 操作,而按地址顺序的 list 需要使用线性时间来找到一个 block 在 list 中的位置,但内存利用率更高。
由于需要足够大的空间来存储前驱后继的指针,explicit free list 的 minimum block size 更大,可能会出现更严重的 internal fragmentation 导致内存利用率下降。
segregated free lists
可以将 block 按 size 分类,例如按 2 的次幂分类,每一类维护一个 list。具体实现方式有很多,例如 simple segregated storage 和 segregated fits。
simple segregated storage
每一类的所有 block 都是这一类的最大 size,如果一类 block 用光了就申请新的 heap 空间,free 时直接放回相应的 list,不合并也不分割。
这样的话,header 和 footer 都不需要了,只需在 free block 里存放一个后继指针即可,但 internal fragmentation 和 external fragmentation 都很严重。
segregated fit
每一类中有不同大小的 block,有分割和合并。allocate 时从相应的类别开始找,在一类中找不到就继续找下一类,这样近似于 best-fit search,但速度很快。
segregated fit 的综合性能较好,所以包括 libc 中的 malloc 函数在内的 allocator 往往选择使用 segregated fit。
buddy system
所有 block size 都是 2 的次幂,分割时每次分成两半直到大小合适,合并时只和 “buddy” 合并。
这里描述清楚可能比较复杂,就感性理解一下,所有的 block 会形成一个如下图所示树状的样子(有点树状数组的感觉),parent 相同的 block 就是 buddy。
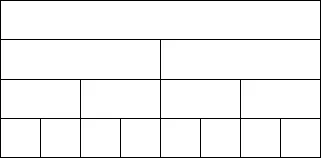
这样的话,搜索和合并会比较快速,但由于 block size 都是 2 的次幂,可能出现严重的 internal fragmentation。
平衡树维护 free block
CS:APP 中没有提到这种方式,但只要理解了上面这几种 free list,就很好理解,free block 不一定要用链表维护,也可以用平衡树维护:在 free block 中存放树的节点所需的 children、parent 等信息,就可以高效实现严格的 best fit,复杂度也不会像 segregated fit 一样在极端情况下发生退化。但是树的节点需要的信息往往比链表多,可能会让 minimum block size 增大到 6 个 word。
我自己写 malloc lab 的时候试着写了个 Splay,发现一般情况下还是比 segregated fit 慢不少,内存利用率也不一定有明显提升,不知道其他平衡树 / 特殊场景下性能如何。倒是在网上看到有说红黑树可以在 malloc lab 拿高分(谁用好的算法拿高分啊,不是考验对着数据调参的能力吗,我觉得我对数据过拟合的 segregated fit 分已经够高了)虚假的 segregated fit:按 block size segregate 来寻找 fit;真正的 segregated fit:按测试数据 segregate 分别进行 fit)。
malloc lab
CS:APP 经典 lab 的代码似乎是可以公开的(
https
Garbage Collection
可以通过 block 之间以及 stack、register、global 变量对 block 的引用关系找到不可达的 block 而进行 garbage collection。
在 C 中,由于没有类型信息,可能会将非指针类型的数据视作对 block 的引用,导致不可达的 block 被视作可达,所以 C 语言的 garbage collection 只能是 conservative 的。