CS:APP 第八章 “Exceptional Control Flow” 的学习笔记。
本章的主要内容为 exception、system call、process、signal、longjmp。
在一般情况下,PC 会按照指令的顺序以及跳转指令来变化。但在很多时候,这样的控制流是不能满足需要的,需要 exceptional control flow (ECF) 作为跳转指令的补充,以处理一些“异常”的或者来自“外部”的变化。
ECF 存在于各个层次,例如:
- 硬件监测到事件发生时调用 exception handler
- 操作系统在不同进程之间进行 context switch
- 不同进程间通过发送 signal 来调用接收者的 signal handler
- 程序内部通过 nonlocal jump 来实现错误处理
Exceptions
exception 是由某种“状态改变”
处理器检测到这种状态改变后,会调用 exception handler,然后跳转到触发前的指令或下一条指令,或者终止整个程序。
Exception Handling
每种 exception 都会有一个 exception number,某些 exception 的 number 由硬件决定,另一些由操作系统决定。
内存中会有一个 exception table,以 exception number 为索引,每一项是对应的 exception handler。处理器中有一个 exception table base register,用来存 exception table 的起始地址,结合 exception number 就可以对每一项寻址。
exception 与 procedure call 的主要区别有:
- procedure call 返回到栈顶存储的返回地址,而 exception 返回到触发时的指令或下一条指令,或终止程序。
- 调用 exception handler 时,会保存包括 condition codes 在内的一些处理器状态,在返回时恢复。
- exception handler 在 kernel mode 下运行,使用的运行栈也是 kernel 的。
Classes of Exceptions
exception 一般有四种:
- interrupt: 异步触发(不是某条指令的执行导致了 exception),返回到下一条指令。一般是由外部 I/O 设备触发(设备通过 interrupt pin 告诉处理器有 interrupt,通过 system bus 发送 exception number,处理器在每执行完一条指令后检查 interrupt pin),触发后调用 interrupt handler,再回到原来的位置继续执行下一条指令。
- trap: 同步触发,返回到下一条指令。比如 system call 是一种常见的 trap,通过
syscall指令主动触发 exception,看上去和函数调用类似,但可以在 kernel mode 下运行。 - fault: 同步触发,返回到触发 exception 的指令或退出。一般来说,fault handler 会尝试解决导致 fault 发生的问题,如果成功解决则返回到触发 exception 的指令,并且能够不再次触发 exception 而继续执行下去;如果没能成功解决,则 abort。
- abort: 同步触发,一定退出。一般代表严重的不可恢复的错误。
Exceptions in Linux/x86-64 Systems
x86-64 中的 fault / abort
- Divide Error Exception (Interrupt 0): 除以零。它是 fault,但实际上 Linux 不会尝试从 divide error 中恢复,而是会直接 abort,一般会显示为 “floating point exception”。
- General Protection Exception (Interrupt 13): 有多种触发原因,例如访问未定义的内存,尝试写入只读的内存段。Linux 也不会尝试从中恢复,而是会直接 abort,一般会显示为 “segmentation fault”。
- Page-Fault Exception (Interrupt 14): page fault 是一个名副其实的 fault,会尝试恢复,详见第九章。
- Machine-Check Exception (Interrupt 18): 严重的硬件错误,是 abort。
(完整列表参见 Intel® 64 and IA-32 Architectures Software Developer Manuals Volume 3A 的 “6.15 EXCEPTION AND INTERRUPT REFERENCE” 一节。)
Linux 中的 system call
Linux 中常用的一些 system call 如 CS:APP Figure 8.10 所示:
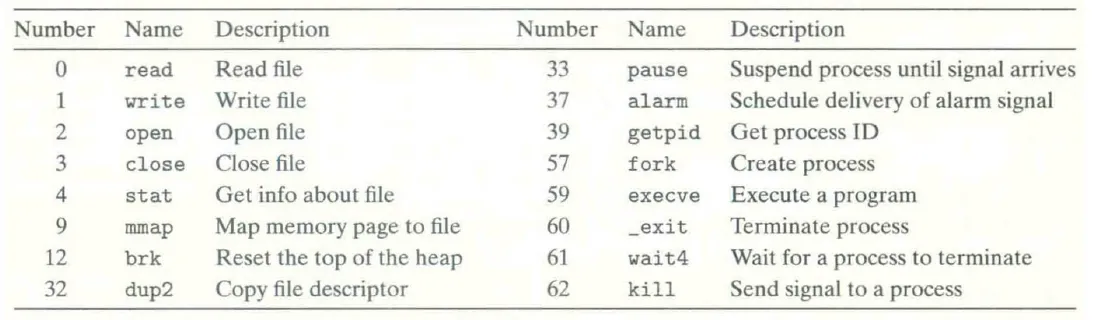
(更多 system call 参见 man syscalls)
在 C 语言中,可以使用 syscall 函数来调用 system call,但一般不这样做,而是使用每个 system call 对应的 wrapper function。syscall 和 wrapper function 统称为 system-level function。
Processes
一个系统中会有很多进程同时运行,但营造出了每个进程都独占了处理器和内存的假象。
进程独占内存的假象是通过每个进程的 private address space 实现的,详见第九章。
Logical / Concurrent Flow
根据一个程序的指令得到的 control flow 称作 logical (control) flow。系统会在不同的进程间来回切换,从一个进程切换出去称作将这个进程 preempt。
如果两个 control flow 的存活时间有重叠,则称它们是 concurrent flow 或它们 run concurrently。这种现象被称作 concurrency,也被称作 multitasking。每次连续执行的同一个 logical flow 中的一段称作一个 time slice,所以 multitasking 也被称作 time slicing。如果两个 logical flow 在不同的 processor core 上运行,则称它们是 parallel flow,run in parallel。
User / Kernel Mode
在处理器中存有一个 mode bit,表示当前是 user mode 还是 kernel mode。只有在 kernel mode 下才能执行某些 privileged instruction、修改 mode bit、访问地址空间中属于 kernel 的区域。
user mode 的程序只能通过 exception 来进入 kernel mode,以执行 privileged instruction 或者访问 kernel 的数据。在 Linux 中,也可以在 user mode 下访问 /proc、/sys 来获得一些 kernel 的数据。
Context Switch
每个进程都有一个 context,包括寄存器内容、PC、user stack、kernel stack、condition codes、page table、process table、file table 等等。
操作系统通过 context switch 来在不同进程间切换,即保存当前进程的 context,恢复要切换到的进程的 context,最后切换过去。context switch 在 exception 中发生,处理 exception 时操作系统中的 scheduler 会决定是否进行 context switch,schedule 到哪个进程。例如:
- 在通过 system call 读取文件时进行 context switch,以在等待读取文件时先执行其他进程;读取到文件后在 interrupt 中再 context switch 回来。
- 系统会周期性地(例如每 1ms)触发 interrupt,从而可以在一个进程执行了一段时间后进行 context switch。
因为程序不知道操作系统会如何 schedule,一般来说,不同进程的执行顺序是没有保证的。
System Call Error Handling
system-level function 一般以返回 -1 代表出错,而将具体的错误记录在全局整型变量 errno (#include <errno.h>),函数 strerror 可以用来根据 errno 得到文字错误信息。
调用 system-level function 时应当检查错误。为了使错误处理更加简便,可以使用类似下面的 wrapper function:
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
void unix_error(char *msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(errno);
}
pid_t Fork(void)
{
pid_t pid = fork();
if (pid < 0)
unix_error("Fork error");
return pid;
}Process Control
C 语言中有很多用来控制 Unix 进程的函数。
获取 PID
每个进程都有一个 PID。
pid_t: 返回当前进程的 PIDgetpid ( void ) pid_t: 返回当前进程的 parent 的 PIDgetppid ( void )
进程的状态
每个进程可能处于三种状态之一:
- Running: 正在运行中,会被 schedule。
- Stopped: 被 suspend 了,不会被 schedule。Stopped 可能是 SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU 导致的,可以由 SIGCONT 恢复运行。
- Terminated: 进程永久地结束了,可能是从
main函数返回、调用了exit函数或者收到了某些 signal。
void exit(int status): 以某个 exit status 将当前进程 terminate
fork
pid_t fork(void): 创建子进程
fork 会将当前进程的所有状态复制一份创建一个新的进程,新的进程有着和原来相同的代码、数据、文件(例如 stdout),但 PID 不同,并且后续对数据的修改是和原进程独立的。
fork 会调用一次,返回两次,分别在两个进程中返回,在 parent 中返回 child 的 PID,在 child 中返回 0,出错则返回 -1。
fork 出的进程和原进程在接下来会执行同一份代码,所以一般会判断 fork 的返回值是否为 0 来让两个进程执行不同的分支。
process group
每个进程会属于一个 process group,每个 process group 有一个 ID。
创建子进程时,子进程会默认处于 parent 的 process group。
pid_t: 返回当前进程的 process group IDgetpgrp ( void ) int: 将setpgid ( pid_t pid , pid_t pgid ) pid对应的进程的 progress group ID 修改为pgid,pid为 0 表示当前进程,pgid为 0 表示修改为pid对应的进程的 PID
wait
pid_t: 等待子进程结束waitpid ( pid_t pid , int * statusp , int options ) pid_t wait(int *statusp):waitpid(- 1 , statusp , 0 )
waitpid 的 pid 参数
参数 pid 决定了要等待的是哪些子进程:
- -1: 所有子进程
- > 0: PID 为
pid的子进程 - 0: process group 与当前进程相同的子进程
- < -1: process group ID 为
-pid的子进程
waitpid 的行为 (options)
默认情况下,waitpid 会等待到有某个被等待的子进程 terminate 再返回,options 可以改变这一行为,其值可以包含下列 flag:
WNOHANG: 立即返回,如果没有符合条件的子进程则返回 0WUNTRACED: 除了 terminate,子进程 stop 也可以结束等待WCONTINUED: 除了 terminate,子进程从 stopped 中 continue 也可以结束等待
reap
除了等待,wait 还会将 terminated 的子进程 reap,即彻底清除掉。没有被 reap 但 terminated 的进程被称作 zombie,会占用一定的系统资源。在 ps 中,zombie 显示为 [defunct]。
如果 parent terminate 了,没有 terminate 的子进程会被设置为 PID 为 1 的 init 进程的子进程,而 zombie 子进程则会被 init reap。
wait 获取子进程的 status
如果 statusp 参数不是 NULL,在 waitpid 返回时 *statusp 内就会存有引起等待结束的那个子进程的信息。
有一系列 macro 可以用来提取 status 中的信息(参数是 *statusp,不是指针):
WIFEXITED: 是否正常退出 (从( status ) main函数返回或调用了exit函数)WEXITSTATUS: 如果正常退出,则返回 exit status (( status ) main函数返回值 /exit函数参数)WIFSIGNALED: 是否由某个 signal terminate( status ) WTERMSIG: 如果是由某个 signal terminate,返回这个 signal( status ) WIFSTOPPED: 是否被 stop( status ) WSTOPSIG: 如果被 stop,返回使其 stop 的 signal( status ) WIFCONTINUED: 是否被 continue( status )
wait 的报错
出错时 wait 会返回 -1,errno 可能是 ECHILD 表示被等待的子进程集合为空,可能是 EINTR 表示 wait 函数被某个 signal 中断了。
wait 会在每有一个子进程结束时返回,但子进程全部结束时会报错 ECHILD,可以利用这一点通过 while 循环来等待所有子进程全部结束。
sleep
unsigned: sleep 若干秒,返回剩余应当 sleep 的秒数(正常情况下没被 interrupt 就是 0)int sleep ( unsigned int secs ) int: 一直 sleep,直到被 signal interrupt,总是返回 -1pause ( void )
execve
intexecve ( const char * filename , char * const argv [], char * const envp [])
execve 会以 argv 作为参数、envp 作为环境变量,在当前进程内执行 executable object file filename。可以和 fork 配合来在子进程内执行其他程序。
argv 是一个以 NULL 为结尾的字符串数组,表示各个参数,其中第一个一般是程序的名称。
envp 也是以 NULL 为结尾的字符串数组,每个字符串形如 name=value。
有一些函数可以用来获取、设置环境变量:
char: 返回* getenv ( const char * name ) NULL或环境变量的值int: 成功则返回 0,失败(setenv ( const char * name , const char * newvalue , int overwrite ) overwrite为 0 而name已存在)则返回 -1voidunsetenv ( const char * name )
Signals
signal 的种类
可以用 man signal.7 查看 signal 的列表(名称、语义、编号、默认行为)。
特别地:
- 除以零时会被发送 SIGFPE
- 执行非法指令时会被发送 SIGILL
- 非法访问内存时会被发送 SIGSEGV
- 按 Ctrl+C 时 foreground process group 会被发送 SIGINT
- 子进程 terminate 时会向 parent 发送 SIGCHLD
- 可以通过 SIGKILL 来强行 terminate 一个进程
signal 的工作流程
- 每个进程会记录每个 signal 是否 pending、是否 blocked
- 发送 signal 会使接收者的这个 signal 变为 pending
- 进程可以改变每个 signal 的 blocked 状态
- 在切换到 user mode 执行进程时,如果一个 signal 处于 pending 状态且没有被 blocked,就会接收这个 signal,并设为没有在 pending
这意味着:
- signal 只记录是否 pending,不会记录发送了几次,在被接收前多次发送只会被接收一次
- 在 blocked 状态下被发送 signal,会在 unblock 时收到
发送 signal
kill 命令
可以用 kill 命令在 shell 中向指定的进程发送信号。一般 shell 会有 builtin 的 kill,也有位于 / 的 kill,可能有一定的区别。
基础的 kill 命令形如 kill -sig pid,其中 -sig 可以形如 -INT/-SIGINT/-2,而 pid 表示要把信号发送给:
- > 0: PID 为
pid的进程 - 0: process group 和当前进程相同的进程
- -1: 除 PID 为 1 的
init外的所有进程 - < 0: process group ID 为
-pid的进程
这与 waitpid 的 pid 参数 是类似的。
在 shell 中使用键盘发送 SIGINT / SIGTSTP
shell 中会有至多一个 foreground job 和零个或若干个 background job。shell 会给每个 job 中的所有进程指定同样的 process group。
Ctrl+C 会向 foreground group 发送 SIGINT,Ctrl+Z 会向 foreground group 发送 SIGTSTP。
使用函数发送 signal
int kill(pid_t pid, int sig): 与 kill 命令类似unsigned: 让 kernel 在int alarm ( unsigned int secs ) secs秒后向当前进程发送 SIGALRM;如果有尚未发送的 alarm 则取消掉,如果secs为 0 则取消后不会发送新的 SIGALRM;没有尚未发送的 alarm 则返回值是 0,否则是被取消的 alarm 还剩的秒数
设置 signal handler
除了 SIGKILL 和 SIGSTOP,其他 signal 的行为可以被改变。
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);函数 signal 用来改变处理 signal signum 的方式。handler 可以是一个函数指针,也可以是 SIG_IGN 表示无视这个 signal,或者 SIG_DFL 表示使用这个 signal 的默认行为。
有 handler 时,接收到一个 signal 就会触发 exception 来执行 handler,在 handler 结束时一般会返回到原来的指令。
在执行 handler 的过程中,相应的 signal 会被 block,但 handler 可以被其他类型的 signal interrupt,在处理完这另一个 signal 后返回到一开始的 handler。
block / unblock signal
进程可以主动 block / unblock 指定的 signal:
intsigprocmask ( int how , const sigset_t * set , sigset_t * oldset )
其中 how 是 SIG_BLOCK / SIG_UNBLOCK / SIG_SETMASK,分别表示 block set 里的 signal / unblock set 里的 signal / 将 blocked set 设为 set。
若 oldset 不是 NULL,则会将修改前的 blocked set 存下来。
还有一些用来设置 sigset_t 的函数:
int: 将sigemptyset ( sigset_t * set ) set设为空int: 将sigfillset ( sigset_t * set ) set设为所有 signalint: 将sigaddset ( sigset_t * set , int signum ) signum加入setint: 将sigdelset ( sigset_t * set , int signum ) signum从set中删去int: 检查sigismember ( const sigset_t * set , int signum ) signum是否在set中,返回 0/1 或出错返回 -1
编写、使用 signal handler
编写安全的 signal handler
由于 signal handler 和主程序并行运行、共享数据,并且主程序可能在意想不到的地方接收到 signal 而被 interrupt,编写安全的 signal handler 是困难的,一般要遵循下面的守则:
- handler 应当尽量简单,例如可以设置一个 flag 而在主程序中检查 flag 并进行处理,而非直接在 handler 中处理
- 在 handler 中只调用 async-signal-safe 的函数(函数列表参见
man),常用的signal - safety printf、sprintf、malloc、exit都不是 async-signal-safe 的 - 存储并恢复
errno,保证调用 handler 前后errno不变 - 访问 handler 与主程序共享的数据时,block signal 以防止在访问的中途被 interrupt
- 把在 handler 中修改而在主程序中访问的的全局变量声明为
volatile的,防止编译器误认为变量没有被修改而错误地进行优化 - 将 flag 声明为
sig_atomic_t类型,它的单次访问是 atomic 的,不会被 interrupt(但先读后写是两次访问,可能被 interrupt)
正确处理多次发送的 signal
多次发送 signal 可能只会收到一次,所以处理 signal 时不能误以为收到的次数与发送的次数相同。
例如,接收 SIGCHLD 来 reap child 时,应当在 handler 中 reap 掉所有已 terminate 的子进程,而非只 reap 一个子进程。
不同系统上 signal handling 的差异
在一些系统上,signal handling 的语义会有区别:
-
在一些系统上,调用了 handler 后这个 signal 就会恢复默认行为,需要在 handler 中重新调用
signal才能一直使用这个 handler。 -
在一些系统上,需要执行较长时间的 system call 会在被 interrupt 后报错 EINTR,而在现代系统上会尽可能地自动重新执行这个 system call,详见
man signal.7的 “Interruption of system calls and library functions by signal handlers” 一节。(P.S. 这就是 Rise of Worse Is Better 中用来举例的 “PC loser-ing problem”,原本采用 worse-is-better 的 Unix 现在也进化成了 the right thing) (P.P.S. 当时读这篇的时候我完全没看懂这一段,没想到现在竟然还能记起来)
可以通过 sigaction 函数来设置想要的 signal handling 语义。
注意 handler 被调用的时机
handler 可能会在意想不到的时机被调用,为了避免出错(race),可能会需要暂时 block signal 来确保 handler 在正确的时机被调用。详见 CS:APP 上的例子。
等待 signal
int: 将 blocked set 设为sigsuspend ( const sigset_t * mask ) mask,在接收到任何 signal 后返回
可以在程序的其他部分 block 掉某个 signal,然后在 sigsuspend 的参数中将其 unblock,以达到等待该 signal 的目的。因为 sigsuspend 等待的不是某个特定的 signal,可以配合 while 循环来检查由 handler 设置的某个 flag。
sigsuspend 的效果类似于下面的这段代码:
sigprocmask(SIG_SETMASK, &mask, &prev);
pause();
sigprocmask(SIG_SETMASK, &prev, NULL);不同的是,上面这段代码有可能会恰好在 sigprocmask 之后、pause 之前接收到 signal,导致这个 signal 没有将 pause interrupt 而一直 sleep 下去。sigsuspend 是 atomic 的,就不存在这样的问题。
Nonlocal Jumps
intsetjmp ( jmp_buf env ) voidlongjmp ( jmp_buf env , int val )
setjmp 会将当前的 PC 和寄存器等信息存在 env 中,而 longjmp 会恢复 env 中保存的信息,跳转到 setjmp 的位置。
这意味着 setjmp 可能返回多次,而 longjmp 不会返回。第一次调用 setjmp 会返回 0,而之后调用 longjmp 时会在 setjmp 的位置返回参数 val 的值(特别地,如果 val 的值是 0,会返回 1,强制和首次返回区分开)。
因为 setjmp / longjmp 只是恢复 PC 和寄存器(包括 %rsp):
- 调用
longjmp时setjmp所在的函数必须还没有返回,否则setjmp所在的 stack frame 就失效了。 setjmp的返回值只应出现在一些简单的表达式中,否则是 UB。特别地,不应将setjmp的返回值赋给一个变量,但可以放在if或switch里。这是考虑到,计算一个复杂的表达式可能会有一些中间量以及 dynamic stack allocation,而longjmp回来时这些中间量、dynamic stack allocation 不一定能被正确恢复,导致表达式不一定能被正确计算。- 如果修改了存放在内存中的局部变量,跳转后会是被修改过的值而不是原来的值,而存放在寄存器中的值则会被恢复。要确保变量不被存在寄存器中,必须使用
volatile声明变量,否则(即便使用了register或auto来声明变量)编译器可能任意地把变量放在内存或寄存器中,造成跳转后变量的值不确定。
intsigsetjmp ( sigjmp_buf env , int savesigs ) voidsiglongjmp ( sigjmp_buf env , int val )
sigsetjmp / siglongjmp 会额外存储、恢复 pending / blocked signal 的信息(需要以非 0 savesigs 调用 sigsetjmp),可以用于 signal handler。
nonlocal jump 主要有两种用途:
- 出错时直接跳转到一个集中的位置来处理错误,而不用一层层往上返回
- 处理 signal 时不返回到被 interrupt 的位置,而跳转到指定的位置
在 signal handler 中使用 nonlocal jump 时需要注意:
- 先
sigsetjmp再 install signal handler,否则可能 race siglongjmp跳转到的后续代码中只能调用 async-signal-safe 的函数
nonlocal jump 可能造成可读性的问题,也可能因为跳过了中间很多函数的返回,造成内存泄露等后果,要谨慎使用。
Tools for Manipulating Processes
strace: 显示程序调用的所有 system call,可以静态链接来避免看到大量共享库相关的输出ps: 列出进程信息top: 列出进程的资源使用(可以用htop)pmap: 查看进程的 memory map/proc: 查看各种进程相关的信息 (man proc.5)