CS:APP 第六章 “The Memory Hierarchy” 的学习笔记。
这章的主要内容有:各种存储设备(RAM、ROM、HDD、SSD)的特点、程序的局部性、缓存的结构以及原理、缓存对程序性能的影响。
因为时间不太够,本来我想先跳过这章以后再补的,但学第九章的时候感觉还是跳不得,否则第九章有些东西感觉学了个半懂。虽然只用学一小部分就足以满足第九章的需求,但我打算摆烂了,该学的东西学不完就学不完,我想学啥就学啥。
Storage Technologies
RAM
Random access memory 分为 SRAM 和 DRAM 两种,SRAM 有更快的访问速度但更加昂贵。
SRAM
SRAM (Static RAM) 将每个 bit 存储在一个 bistable 的 memory cell 中,每个 cell 由 6 个晶体管组成,有两种可能的稳定态,遇到微小的扰动也会迅速恢复到这两种状态之一。
DRAM
DRAM (Dynamic RAM) 将每个 bit 存储在一个很小的电容中,容易受到外界干扰,所以需要周期性地将数据复制出去再复制回来以进行刷新,可能还会配合纠错码来保证数据正确。
DRAM 的设计使其存储密度更高,但访问速度更慢;SRAM 则更快,但密度更低,更贵,更费电。访问 DRAM 的用时大约是 SRAM 的 10 倍,而 SRAM 的造价大约是 DRAM 的 1000 倍。
Conventional DRAM
DRAM 芯片被分为若干 supercell,每个 supercell 存储一个 word,一般是 1 byte。supercell 排列为二维阵列,可以用二维坐标 定位。
DRAM 通过 pin 连接到 memory controller 来和外界通信。读取位于 的 supercell 时,memory controller 会依次发送 row access strobe (RAS) 和 column access strobe (CAS) ,在收到 RAS 后 DRAM 会将第 行复制到一个内部的 row buffer,收到 CAS 后再从 row buffer 里将第 列发送给 memory controller。
Memory Module
DRAM 芯片会被组装为 memory module 来插到主板上。
DIMM 是一种 memory module。例如,一个 DIMM 可以包含 8 个 DRAM 芯片,每个 64-bit 的 word 在每个 DRAM 芯片的同一个地址上分别存一个 byte,从而整个 DIMM 可以以 64-bit 为单位与外界通信。
Enhanced DRAM
朴素的 DRAM 是比较慢的,历史上曾经有过若干对 conventional DRAM 的优化:
- FPM (fast page mode) DRAM: 如果连续两次 RAS 是一样的,可以省略掉后续相同的 RAS,直接发送 CAS
- EDO (extended data out) DRAM: 延长了数据输出的时间,对 pipelining 有帮助
- SDRAM (synchronous): 通过时钟信号的 rising edge 同步地通信,而非通过发送 RAS/CAS 异步通信
- DDR (double data-rate) SDRAM: 通过同时使用时钟信号的 rising edge 和 falling edge 达到 double data-rate,分为 DDR、DDR2、DDR3、DDR4、DDR5 等
- VRAM (video): 一般用于显卡、frame buffer 等,它的输出是直接输出整个 buffer,并且可以并行地同时读和写
ROM
RAM 会在断电后丢失数据,所以是 volatile 的。与之相对,还有 nonvolatile 的存储器,统称为 read-only memory (ROM),尽管有的 ROM 是可以写入的。ROM 的写入称作 reprogram。
- PROM (programmable ROM) 只能被写入一次。
- EPROM (erasable PROM) 需要用特殊设备写入,可以写入大约 1000 次。
- EEPROM (electrically EPROM) 不需要用特殊设备就可以写入,可以写入大约 次。
- flash memory 是一种基于 EEPROM 的 nonvolatile 存储器,被广泛使用,包括用于 SSD。
- 固件 (firmware) 往往存储于 ROM 中。
访问 main memory
一个 bus 是一组用来通信的导线,可以传输地址、数据、控制信号等。CPU 和 main memory 之间的通信通过 bus transaction 进行。
CPU 通过 system bus 连接 I/O bridge,I/O bridge 通过 memory bus 连接 main memory。I/O bridge 负责 system bus signal 和 memory bus signal 之间的转换。
HDD
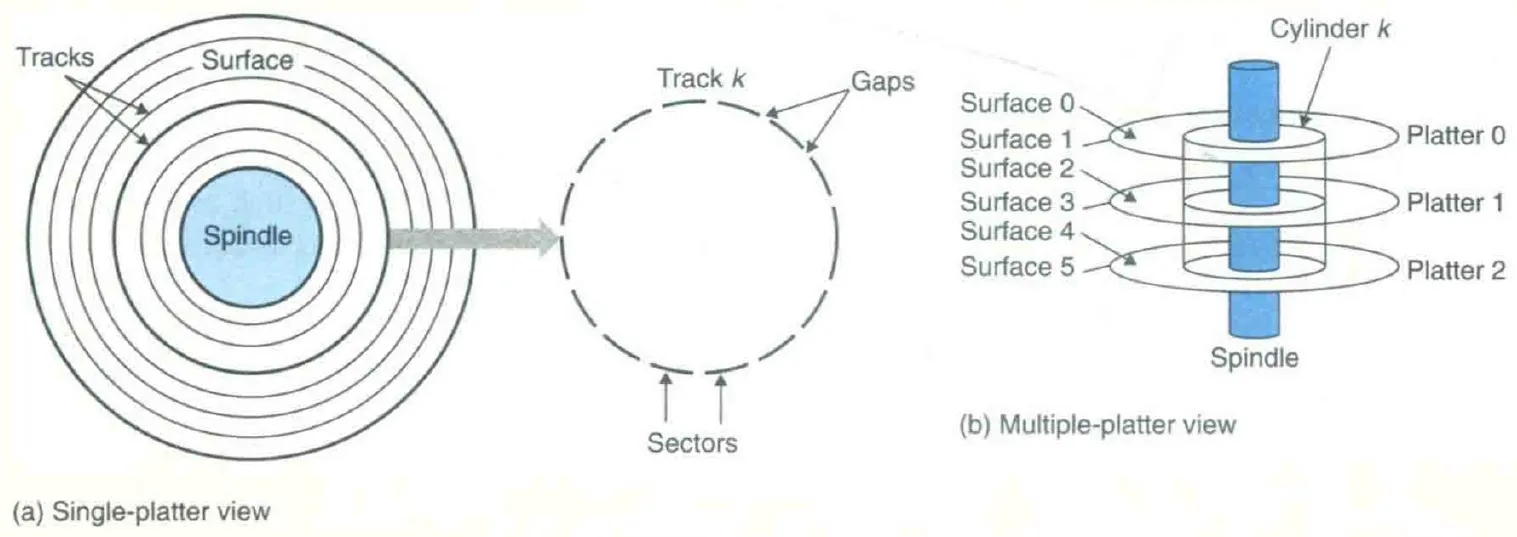
磁盘的结构
磁盘由若干 platter(盘片)组成。每个 platter 有两个 surface(表面),每个 surface 上覆盖着磁性记录材料。platter 由位于中心的 spindle(主轴)带动,以某个一般是 5400~15000 RPM 的速度转动。
每个 surface 被分成若干个称作 track(磁道)的同心圆环,每个 track 被分为若干 sector(扇区)。每个 sector 存有相同大小的数据(一般是 512 bytes),相邻的 sector 之间由 gap(间隙)隔开,gap 不存储数据,而是用来识别 sector。
一个磁盘通常由多个堆叠在一起的 platter 构成,这些 platter 共享一个 spindle。对于某个距离 ,一个磁盘内所有 surface 上离转轴距离为 的 track 的集合称作一个 cylinder(柱面)。
整体结构如 CS:APP Figure 6.9 所示:
磁盘的容量
磁盘的容量有三个衡量指标:
- recording density: 单位长度的 track 存储的 bit 数量
- track density: 单位长度的半径上的 track 个数
- areal density: 单位面积上存储的 bit 数量
早期的磁盘的所有 track 都有相同数量的 sector,这样的话位于外部的 track 的 sector 就会更加稀疏。后来为了提高容量,将 cylinder 划分成了若干个 recording zone,每个 recording zone 由若干相邻的 cylinder 组成,同一个 recording zone 内的所有 track 有相同数量的 sector。
磁盘的读写
磁盘通过连在传动臂上的读写头进行读写,每次读写前需要先将读写头移动到相应的位置(寻道),并等待目标 sector 转动到读写头下,再开始读写。
寻道用时与读写头原本的位置到目标位置的距离有关,等待转动的用时则看运气。在 CS:APP 举的例子中,寻道平均用时为 9 ms,等待旋转平均用时为 4 ms,读写一个 sector 用时 20 μs。
也就是说,磁盘读写的主要用时是寻道以及等待旋转用时,也就是初次访问一段连续的 sector 的用时,而与访问多少个连续的 sector 关系不大。对于单个 sector,磁盘访问的用时可以达到 SRAM 的 倍,DRAM 的 倍,但连续 sector 的读写用时仅为 DRAM 的不到十倍。
Logical Disk Blocks
磁盘对外提供了 logical block 作为 sector 的抽象,每个 logical block 的大小和一个 sector 相同,由连续的非负整数索引,通过 disk controller 翻译成形如 (surface, track, sector) 的坐标。
I/O bus
不同的 I/O 设备通过 I/O bus 与 I/O bridge 连接。例如显卡、连接各种设备的 USB controller、通过 SCSI/SATA 等接口连接磁盘的 host bus adapter 等都会连接到 I/O bus。
访问磁盘
访问磁盘需要向磁盘发送三条指令:
- 向磁盘发送一个信号,告诉磁盘要读取数据
- 将要读取的 logical block number 发送给磁盘
- 告诉磁盘读取到的数据要放在 main memory 的哪个地址
发送完这些指令后,CPU 会继续干其他事情。磁盘读取到数据后,会通过 I/O bus 直接将数据存放到 main memory 中而不经过 CPU,这被称作 direct memory access (DMA)。存放好数据后,磁盘向 CPU 发送 interrupt signal 来跳转到处理磁盘读取完成的 signal handler。
SSD
SSD 将一个或多个 flash memory 包装起来,并且有一个 flash translation layer 来将输入的 logical block number 转换为对 flash memory 的访问,对外表现出与 HDD 类似的接口。
flash memory 由若干 block 组成,每个 block 又由若干(32-128 个)page 组成,每个 page 一般是 512B-4KB 大,数据传输的最小单位是 page。
SSD 的写入比较特殊:一个 page 需要在所属的整个 block 都被擦除(改为全 1)后才能写入一次,如果要写入第二次就得再把整个 block 擦除一遍。在写入时,为了擦除某个 block,可能会需要把这个 block 存储的数据复制到其他 block。擦除是一个耗时相对较长的操作,需要约 1 ms,并且每个 block 在擦除约 次后就会损坏。
这使得 SSD 的写入比读取略慢,并且写入很多次后可能损坏。flash translation layer 会通过 wear-leveling logic 来尽可能使得每个 block 的擦除次数相同,以延长 SSD 的使用寿命。
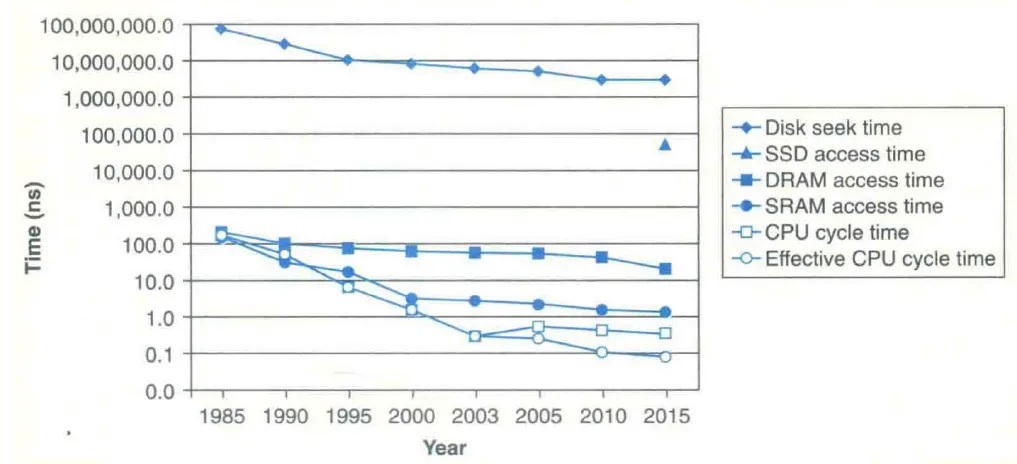
disk、RAM、CPU 速度差异的历史变化如 CS:APP Figure 6.16 所示,其中 CPU cycle time 是单核的,effective CPU cycle time 是多核的:
Locality
好的程序具有良好的 locality。locality 有两种表现形式,temporal locality 指的是最近访问过的数据更有可能在不久的将来再次被访问,spatial locality 指的是访问过一处的数据后更有可能在不久的将来访问邻近的其他数据。
具有良好 locality 的程序跑得更快,因为计算机系统设计的各个层面都利用 locality 做了优化。
一些 locality 的例子:
- 重复引用同一个变量的程序有良好的 locality。
- 在一段连续内存(数组)中依次访问每个元素称作 stride-1 reference pattern,每次间隔 个元素进行访问称作 stride-k reference pattern, 越小 locality 越好。遍历高维数组时尤其要注意访问的顺序。
- 由于循环会重复访问同一段指令,循环的指令读取局部性良好
The Memory Hierarchy
在硬件上,不同存储技术之间存在性能、价格、容量的 trade-off;在软件上,程序具有 locality。硬件和软件的这两条性质正好可以搭配在一起,促使 memory system 采用了如 CS:APP Figure 6.21 所示的称作 memory hierarchy 的组织方式:
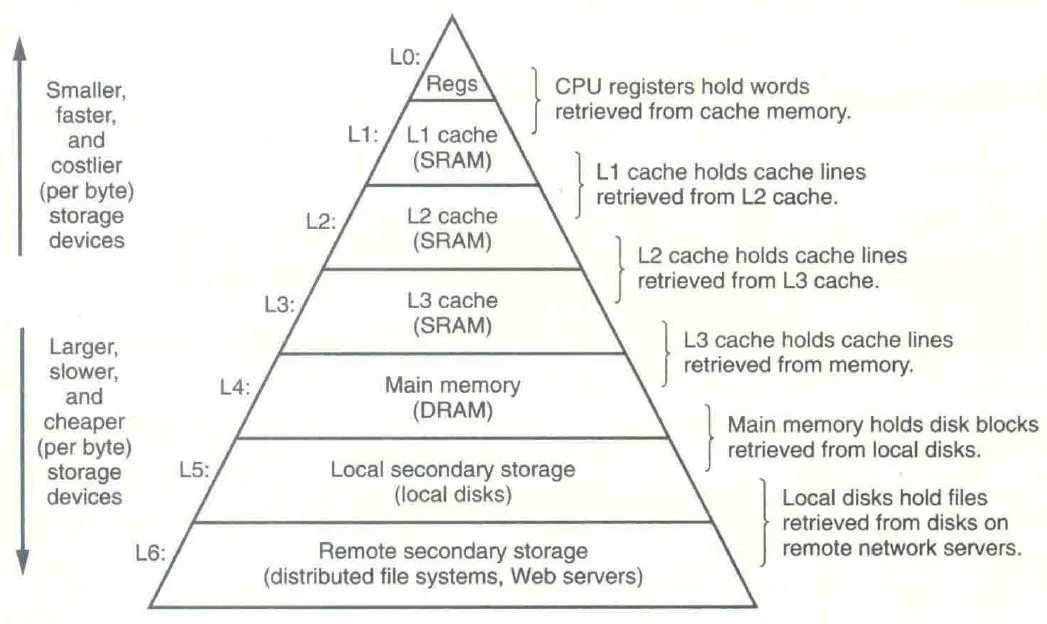
memory hierarchy 的构成并不一定和上图完全一致,例如 SRAM 的级数可能不是三级、DRAM 和 HDD 间可能还有 SSD、磁带也可以作为 memory hierarchy 中比 HDD 更低的一级。
Cache
caching 指的是用一个相对小而快的存储设备来存储一个相对大而慢的存储设备中最为活跃的部分,这个小的存储设备称作大的存储设备的 cache。
在 memory hierarchy 中,每一级都是下一级的 cache。数据会在各个相邻层级间不断地传输,不同层级之间会以不同的 block size 作为数据传输的基本单位。
从 cache 获取数据
想要从 memory hierarchy 的某一级获取数据时,首先会尝试从它的 cache 获取数据,如果成功获取则称作 cache hit,否则称作 cache miss。
发生 cache miss 时,一般会先将数据从下一级复制到上一级,从而最终还是表现为从 cache 中获取数据。如果 cache 满了,在从下一级获取数据时,就需要删除 cache 中的一些数据来腾出空间,这时需要在 cache 中选择被删除的数据,被删除的 block 称作 victim block,这个行为称作将 victim block evict,而选择 victim block 是根据 replacement policy 进行的,例如 random replacement policy、least recently used (LRU) replacement policy 等。
Cache 的管理
cache 可能由硬件、OS、软件以及它们之间的相互配合来进行管理,而这在大部分时候都是自动完成的,无需应用程序的程序员操心。
各级 cache 如 CS:APP Figure 6.23 所示:

Cache 对 locality 的利用
temporal locality 使得重复使用的数据留存在 cache 中从而更容易 cache hit;cache 中的数据按 block 存储则利用了 spatial locality,使得一个数据被 cache 时与其邻近的处于同一个 block 的数据也被 cache。
Cache Memories
随着 CPU 和 DRAM 的速度差异越来越大,SRAM 被用来填充它们之间的 gap。
在下面的讨论中,为了简便,假设只有 L1 cache,没有 L2、L3 cache。
Cache 的结构与读取
设 main memory 有 个地址,每个地址存放一个 byte。它的 cache 会分成 个 cache set,每个 cache set 包含 个 cache line,每个 cache line 存放一个大小为 byte 的 data block、一个 valid bit、以及长度为 的 tag bits。
每个地址会被分成三部分,高位的 位是 tag,中间 位是 set index,低位 位是 block offset。获取存放在某个地址的数据时,先根据其 set index 找到对应的 cache set,再在 cache set 中找到 valid bit 为 1 且 tag 相符的 cache line,最后通过 block offset 来从 block 中提取出单个 byte。
在 cache miss 时,需要从下一级获取数据,存放到 cache 中。如果对应的 cache set 所有 cache line 都满了,就需要 evict 某个已有的 cache line。
Conflict Miss
cache set 的设计基于一个假设,即在局部内访问的数据地址的低位往往是不同的,但实际上可能并非如此。如果以 的倍数为地址间隔访问数据,就可能连续访问同一个 cache set 内的数据,导致 cache miss( 较小,尤其是 时,这种情况更可能触发)。例如,数组的大小是 的次幂而交替访问相邻数组的同一个下标时就可能这样。
Cache 的分类
的 cache 称作 direct-mapped cache。书上在这仔细解释了半天,感觉废话好多啊。)
的 cache 称作 set associative cache。其中, 的称作 E-way set associative cache,而 的称作 fully associative cache。
Cache 的写入
在 cache hit 时,有两种处理方式:
- write-through: 既修改 cache,又修改下一级
- write-back: 只修改 cache,并且在每个 cache line 中添加一个 dirty bit,用来记录是否被修改过,在被 evict 时若 dirty 则写入下一级
在 cache miss 时,也有两种处理方式:
- write-allocate: 先从下一级获取数据,然后用与 cache hit 相同的处理方式
- no-write-allocate: 直接写入下一级,不获取到 cache 中
一般 write-through 和 no-write-allocate 搭配,write-back 和 write-allocate 搭配。
实际上,cache 写入的优化是非常复杂的问题,这里只是简单介绍了一下。作为程序员,可以把 cache 写入当成是 write-back、write-allocate 的。
i-cache 和 d-cache
只存放指令的 cache 称作 i-cache,只存放数据的 cache 称作 d-cache,都存放的 cache 称作 unified cache。
将 i-cache 和 d-cache 分开,就可以对它们分别进行优化,例如 i-cache 是只读的,二者可以有不一样的大小、不一样的 cache set 设置。将两者分开还可以一定程度上避免 conflict miss。
在 Core i7 处理器中,每个核有自己的 L1 i-cache、L1 d-cache、L2 unified cache,所有核共享一个 L3 unified cache。
Cache 的性能
cache 性能的衡量指标有:
- miss rate
- hit rate
- hit time: cache hit 时的访问用时
- miss penalty: cache miss 时的访问用时,与最终从哪一级获取到数据有关
一般来说,cache 的参数对性能的影响是:
- cache size 越大,hit rate 就越高,但速度会慢。
- 增大 block size 可以更好地利用 spatial locality,但也有可能因 cache line 数量减少而降低 hit rate,并且会因为每次需要传递的数据变多而增大 miss penalty。
- 更大的 可以降低 conflict miss 的可能性,但也会使得 tag 匹配以及 victim line 的选择更加复杂,从而增大 hit time 和 miss penalty。在 Core i7 处理器中,L1、L2 cache 是 8-way 的,L3 cache 是 16-way 的。
- write-through 实现起来更加容易,并且在 read miss 时不会触发写入。而 write-back 可以减少数据传递的总量,降低 I/O bus 带宽的占用,也可能降低数据传递的用时。一般来说,memory hierarchy 中较低的层级更倾向于使用 write-back。
The Impact of Caches on Program Performance
The Memory Mountain
对一定 size 的数据按照一定的 stride 进行访问,将 size、stride 与数据吞吐量的关系画成三维图像,就得到了 memory mountain。
CS:APP Figure 6.41 展示了一座 Core i7 的 memory mountain:(这也是 CS:APP 的封面)
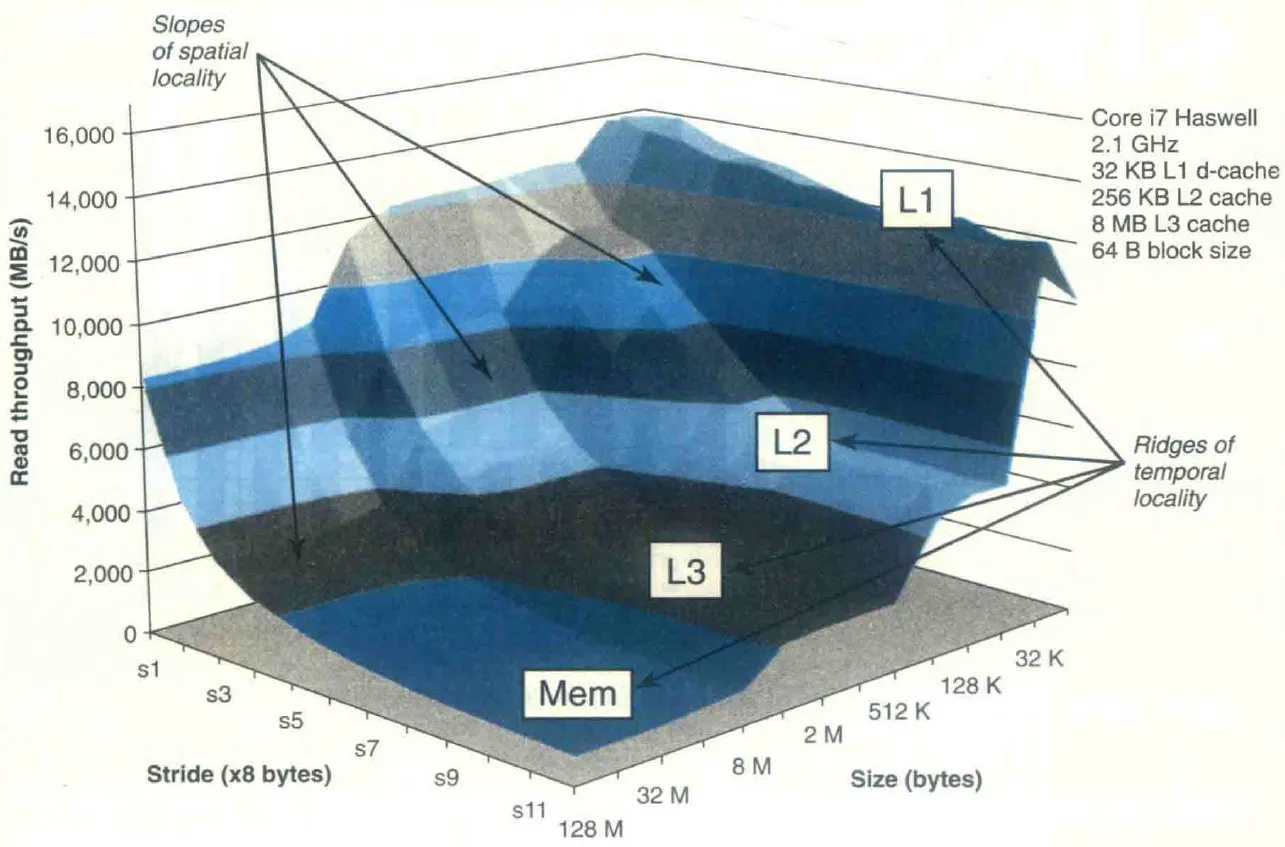
Memory mountain 较为完整地呈现了一个 memory system 的性能,以及 temporal locality 和 spatial locality 对性能的影响。
在每级 cache 的容量处,吞吐量会发生明显的突变。
在 size 相同时,stride 越小吞吐量越高。在 stride 接近 1 时变化尤其明显,这和 Core i7 系统的 prefetching 技术息息相关,处理器能够识别出 stride-1 reference pattern 并在实际访问到数据之前就进行 prefetch。
矩阵乘法的循环顺序
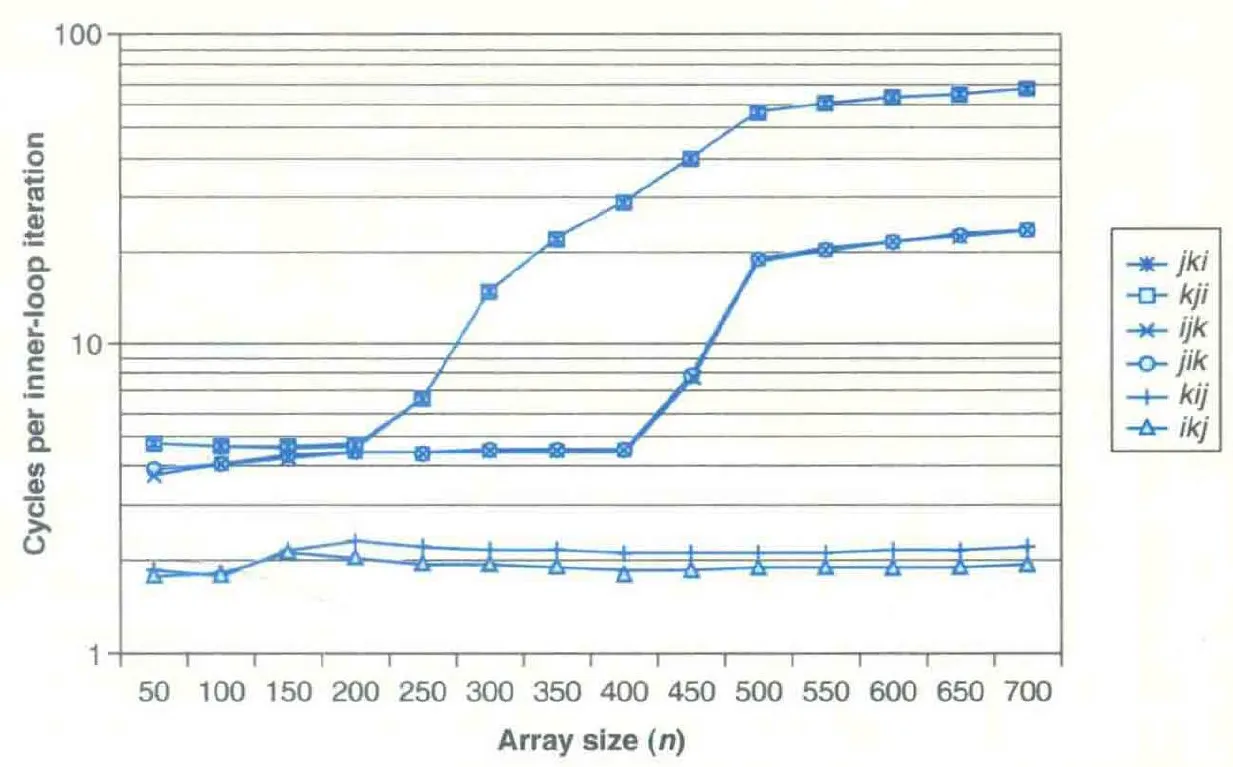
(书上在这讲了半天,感觉废话好多,我就放个测试结果上来吧。)